Enterprise Data Mesh (EDM) Reference Architecture
Concept of Operations
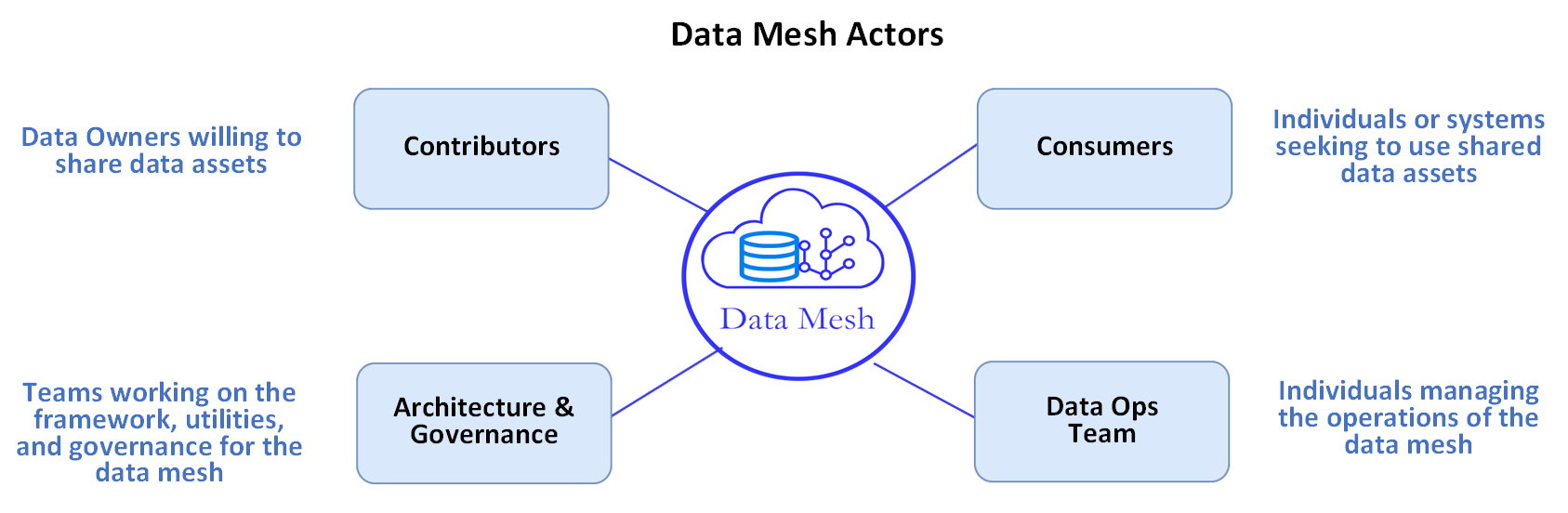
- Data Contributors provide access approval, protect, and share their data with the community
- Data Consumers access shared data assets either System-to-System or by bringing their own Query and Analytic Tools
- The Data Ops Team manages the infrastructure and security tools that support the Data Mesh
- The Data Mesh community collaborates to develop and sustain the Architecture and Governance
Core Technical Patterns
Standard Formats for Design and Technology Independence
Utilize robust and highly scalable storage such as AWS S3, within the enclave of data contributors, employing widely accepted formats like Apache Parquet (Parquet): The CMS Enterprise Data Mesh (EDM) project provides value by preventing replication of multiple data sources which will help to resolve data inefficiency, duplication, inconsistency, poor quality, and increased costs for associated infrastructures. This results in data segregated from any particular technology or compute and equally available to all query and data processing engines. Parquet is an open columnar data format and widely adopted and supported by big data tools in the marketplace. It supports a variety of data compression algorithms, are split-able, binary formats and thus optimized for scalability and massively parallel processing. Similar benefits cannot be achieved with JSON, Apache Avro (row-oriented data serialization framework) or CSV data formats, for example. Most data processing tools like Apache NiFi, AWS Glue etc. support conversion of raw data to Parquet. Some high-level factors to consider: Spark query processors have cost optimizers adapted for Parquet. It should be noted, however, that results may vary depending on query and data specifics. Parquet does not support ACID (Atomicity, Consistency, Isolation, Durability) transactions and this needs to be considered for data updates unless using immutable data sets. This data standard is one of the most active among data standards. Performance continues to improve as indexing, data metrics and metadata information are being added to these formats to support faster processing and analytics. Another key consideration to keep in mind in thinking about data in S3 is that the data is closer to a typical normalized database table on S3 rather than a consolidated or de-normalized extract from a system or database. In other words, the data in S3 coupled with the appropriate compute on the front end like a Redshift Spectrum, Athena, EMR etc. can act as a data warehouse or query database as appropriate. Currently, only the Parquet format is permitted, but other formats may eventually be available in the future as the enterprise data matures.
Package Data for Performance and Ease of Access
Adopt a partitioning and bucketing strategy for data based on major business use cases: This creates a performant data mesh that meets the high-level performance requirements for the enterprise. Specific consumers can create further performance optimizations as required. The partitioning and bucketing referenced here is Hive partitioning. Hive partitions are an open standard based on Hive to partition large data sets and are widely supported. Optimal partitioning is a requirement and key to achieving massively scalable performance and can also help with predicate pushdowns where appropriate. There is an abundance of material online dedicated to the science and art of partitioning and bucketing. Optimal partitioning and bucketing strategy start with a good understanding of the data, types of analytics queries and expected mechanisms to keep data updated. Leveraging often used query predicates to determine your partitioning approach is a good place to start.
Empowering System to Data Mesh Consumers with Metadata
Maintain metadata for the Data Mesh in a centralized common repository such as Hive Metastore: This allows the Data Mesh to be seamlessly shared across multiple processing engines such Spark, Presto, Databricks, Snowflake etc. on-demand, without being locked into any one of them. Components can extend the data as required for specific use cases and contribute to the Mesh at the same time. The Hive Metastore provides a simple mechanism to project structure onto large amounts of unstructured and/or structured data by applying a table schema on top of the data. This table abstraction of the underlying data structures, their relationships, and file locations present users with a relational view of data in S3. The Hive Metastore is also a near-universal format for query and analytic computes to auto-discover and query the Data Mesh on demand. For example, with information from the metadata store, a brand-new presto cluster can immediately query the data upon spin-up.
Data Consumers
There are two types of data consumers. A data consumer is either a system-to-Enterprise-Data-Mesh consumer or an end-user-to-Enterprise-Data-Mesh consumer using shared data from the Enterprise Data Mesh.
System-to-Enterprise-Data-Mesh consumers
System-to-data-mesh consumers engage with data contributors to allow for developed applications to access shared data assets connected to the data mesh. System-to-data-mesh consumers can request AWS Identity Access Management (IAM) access rights from data contributors, who are responsible for implementing these AWS IAM access controls at the AWS S3 bucket and data object levels. When a data contributor grants these rights, the system-to-data-mesh consumer’s applications will be able to access the data contributor’s assets managed within the AWS S3 buckets in the EDM. System-to-data-lake consumers use the System to Data Mesh Design Pattern.
IDRC Snowflake Data Share as a Consumer: Current IDRC users will retrieve MDM data through the IDRC system. To gain access to MDM data products in IDRC, users should visit the IDRC Snowflake Data Share Confluence page to understand the onboarding process and submit an onboarding form.End-user-to-Enterprise-Data-Mesh consumers
The end-user-to-data mesh design pattern describes how end user-to-data mesh consumers will employ selected query, analytics, data access tools, and other options in the cloud to access data in whatever manner meets their business needs. Teams are currently evaluating data protection products and methods to choose a solution that will enable data contributors to grant access to various users and groups using role-based security. In addition, the user-facing User Data Catalog (containing source system metadata) allows end users to search for data assets that can support specific needs, browse the array of available data assets, and review their structures and “demographics” (such as the data contributor, the size of the data asset, the number of records, date of last update, etc.). End-user-to-data-mesh consumers use the End-User to Data Mesh Design Pattern.
Accessing the data mesh
Data consumers have three options for accessing the Enterprise Data Mesh. Interested organizations should review the Become a Data Consumer Confluence page to learn the different options to onboard to the Enterprise Data Mesh as a Consumer.
- Launchpad
Launchpad is a service offering from EDM to allow interested teams with no cloud footprint and/or ADO a way to consume production-level data for analysis and visualization. The EDM Ops team provisions required AWS services for Data Analysts to spend less time on setup and more time on data analysis. - Workspaces
EDM Workspaces allow individual users to quickly access data through a preconfigured AWS virtual desktop (AWS WorkSpace) with tools to analyze and visualize data sets available in the Enterprise Data Mesh. These virtual desktops are integrated with Active Directory and Okta Single Sign-On (SSO) for seamless authentication and authorization with CMS EUA and IDM user accounts. This option is best suited for individual Data Scientists or Business Analysts with no AWS infrastructure experience as the EDM Ops team will provide access to available data sets while managing the compute and infrastructure resources needed. - EDM Snowflake Data Share
For organizations that utilize Snowflake, the consuming system can be granted access to the Enterprise Data Mesh Snowflake data share for available data products. The Consumer Onboarding Questionnaire contains a current list of MDM, DDPS, and IDRC data assets available through the IDRC Snowflake Data Share (as noted above).
Data Contributors
A data contributor is a source data owner that provides the approval and the opportunity for data mesh consumers to access their data. Data contributors agree to observe defined guidelines and governance practices that are standard across the Enterprise Data Mesh. Data contributors prepare their data for use and make their data assets discoverable and accessible by updating the Hive Metastore. Shared data asset remains within the data owner’s security boundary — the data contributor’s Authority to Operate (ATO) includes their data assets connected to the data mesh . Therefore, the data contributor is responsible for determining and overseeing data access rights and protections that are appropriate for the use of their data. For the System to Data Mesh Design Pattern those rights will be agreed upon between the data contributor and the organization developing the consuming system. For the End-User to Data Mesh Design Pattern, when available, data consumers will work with a Dev Ops team to create policies and provide access.
Enterprise Data Mesh Onboarding
The following workflows are used by the EDM Data Ops team to onboard Data Contributors or System to Data Lake Consumers. The first step in each request process is to submit either a Contributor Request or a specific Data Consumer request from the Enterprise Data Mesh Initiative Home Page..
Data Contributor Onboarding
The following diagram summarizes the onboarding flow for Data Contributors.
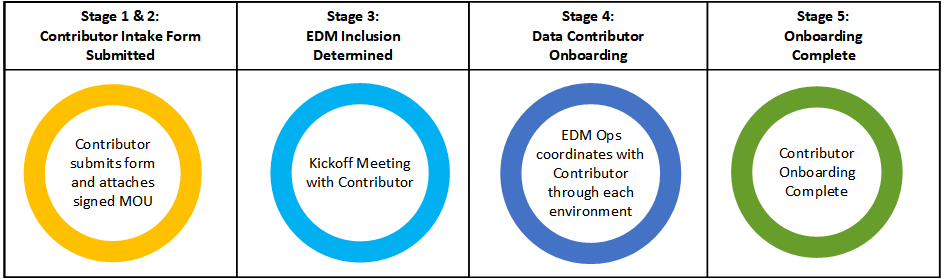
- Stages 1& 2: Contributor Intake Request Submitted
— Contributor submits request and attaches signed MOU - Stage 3: EDM Inclusion Determined
— Kickoff Meeting with Contributor - Stage 4: Data Contributor Onboarding
— EDM Ops coordinates with Contributor through each environment - Stage 5: Onboarding Complete
— Contributor Onboarding Complete
Technical implementation includes the following steps (find more detail at Pathways for Contributors):
Contributor VPC
- Create an S3 bucket with Hive Query Language (HQL) metadata and Parquet data extracts.
- Provide read-only access for the EDM IAM role.
EDM VPC
- Provide IAM role to Contributor for read-only access to S3 data bucket.
- Execute script in EMR to retrieve the HQL file from the Contributor bucket and register the metadata into RDS Aurora.
- Schedule execution of the script for automated refresh of the metadata.
Data Consumer Onboarding
The following diagram summarizes the onboarding flow for Standard Data Consumers.

- Stages 1 & 2: Consumer Request Submitted
— Consumer submits form and attaches signed MOU - Stage 3: Initial Review by EDM Ops Team
— EDM Ops reviews with internal team and confirms data availability - Stage 4: CMS Contributor Verification
— EDM Ops notifies Contributor of Consumer Request
— Data Contributor grants approval for Consumer access to requested data set - Stage 5: Review with Data Consumer
— Kickoff meeting with Consumer - Stage 6: Coordination with Data Contributor
— Contributor Data Access Configurations Performed - Stage 7: Data Access Provided
— Consumer Access Provisioning - Stage 8: Onboarding Complete
— Consumer Access Granted to Contributor Datasets
Technical implementation includes the following steps (see Become a Data Consumer for other consuming options):
EDM VPC
- Allowlist the Consumer’s “Endpoint Service” account as one of the trusted principals.
- Provide the “Endpoint Service” name i.e., the “Service Name” to the Consumer.
- Accept the Consumer’s connection request to the “Endpoint Service.”
Contributor VPC
- Provide read-only access for the Consumer IAM role to the S3 bucket.
Consumer VPC
- Create the endpoint with the “Endpoint Service” name provided by the EDM Team.
- Provide Consumer IAM role for EDM to grant read-only access to the S3 data bucket.
- Consumers can connect to the VPC Endpoint Network Interface DNS name from any of the computers that they wish to use to the EDM Hive Metastore.
Data Catalogs
The Enterprise Data Mesh Initiative differentiates between the internal, technical metadata store (compute catalog) and the external-facing consumer/contributor metadata store and user interface (user data catalog).
The compute catalog stores all the structure information of the various databases, tables, and partitions in the mesh , including column and column type information. Implemented using Apache Hive Metastore.
The EDM’s user data catalog, the Enterprise User Data Catalog (EUDC), stores profile information about the data assets [and/or datasets] in the EDM, supports data asset discovery and access and makes structure metadata accessible to data consumers.
For further detailed information on the data catalog, including standards, assessments, briefings and ConOps please refer to the Enterprise Data Mesh data catalog guidance.