To ensure the audience fully understands the conceptual foundation for this guidance, the following terms, definitions, and explanations are presented in a sequence that progressively build the foundation for the guidance. The Glossary defines additional terms for the reader’s benefit.
Continuity of Operations (COOP)
COOP is an effort within the Executive Office of the President and individual Departments and Agencies to ensure that essential functions continue to be performed during disruption of normal operations.
COOP focuses on restoring organization’s Mission Essential Functions (MEF) at an alternate site and performing those functions until normal operations can be resumed.
Disaster
Any event, whether human-caused, act of nature, or technology failure, that causes disruption to operations beyond acceptable time limits, thereby threatening the survival of critical services.
Disaster Recovery Plan
A plan which is executed that is designed to restore and resume normal IT operations after an event of a disaster within an acceptable timeframe as determined by the agency. Plans exist at both system and enterprise levels.
National Essential Functions (NEF)
The NEFs represent the overarching responsibilities of the Federal Government to lead and sustain the Nation and shall be the primary focus of the Federal Government leadership during a catastrophic emergency.
Primary Mission Essential Functions (PMEF)
PMEFs are those validated MEFs that must be performed to support or implement the uninterrupted performance of NEFs.
Mission Essential Functions (MEF)
MEFs are the essential functions directly related to accomplishing the organization’s mission as set forth in statutory or executive charter. MEFs may be unique to each organization. MEFs serve as key continuity planning factors for Department/Agencies to determine appropriate staffing, communications, information, facilities, training, and other requirements in an event of a disaster.
Essential Supporting Activities (ESA)
A subset of government functions that are determined to be critical activities. Functions that support performance of MEFs; and must be included in the organization’s DR planning process.
High Value Assets (HVA)
All MEFs’ supporting systems and ESAs are considered HVAs according to the Office of the Federal Chief Information Officer. HVAs are:
“Federal information systems, information, and data for which an unauthorized access, use, disclosure, disruption, modification, or destruction could cause a significant impact to the United States’ national security interests, foreign relations, economy, or to the public confidence, civil liberties, or public health and safety of the American people. HVAs may contain sensitive controls, instructions, data used in critical Federal operations, or unique collections of data (by size or content), or support an agency’s mission essential functions, making them of specific value to criminal, politically motivated, or state sponsored actor for either direct exploitation or to cause a loss of confidence in the U.S. Government.”
High Availability Assets (HAA)
HAAs are IT technology architecture where redundancy and failover processes are built into a system to maximize uptime and availability. The concept of HA is to achieve an uptime of 99.999 percent or higher, which equates to just a few minutes per year of downtime.
On Premises Hot Site
Hot sites are locations that operate 24 hours a day with fully operational equipment and capacity to immediately assume operations upon loss of the primary facility. A hot continuity facility requires on-site telecommunications, information, infrastructure, equipment, back-up data repositories, and personnel required to sustain essential functions.
On Premises Warm Site
Warm Sites are partially equipped office spaces that contain some or all of the system hardware, software, telecommunications, and power sources. To become active, a warm facility requires additional personnel, equipment, supplies, software, or customization. Warm sites generally possess the resources necessary to sustain critical mission/business processes but lack the capacity to activate all systems or components.
On Premises Cold Site
Cold Sites are typically facilities with adequate space and infrastructure (electric power, telecommunications connections, and environmental controls) to support information system recovery activities. These facilities are typically neither staffed nor operational daily. Teams of specialized personnel must be deployed to activate the systems before the site can become operational. Although, basic infrastructure and environmental controls are present (e.g., electrical and heating, ventilation and air conditioning systems), systems are not continuously active.
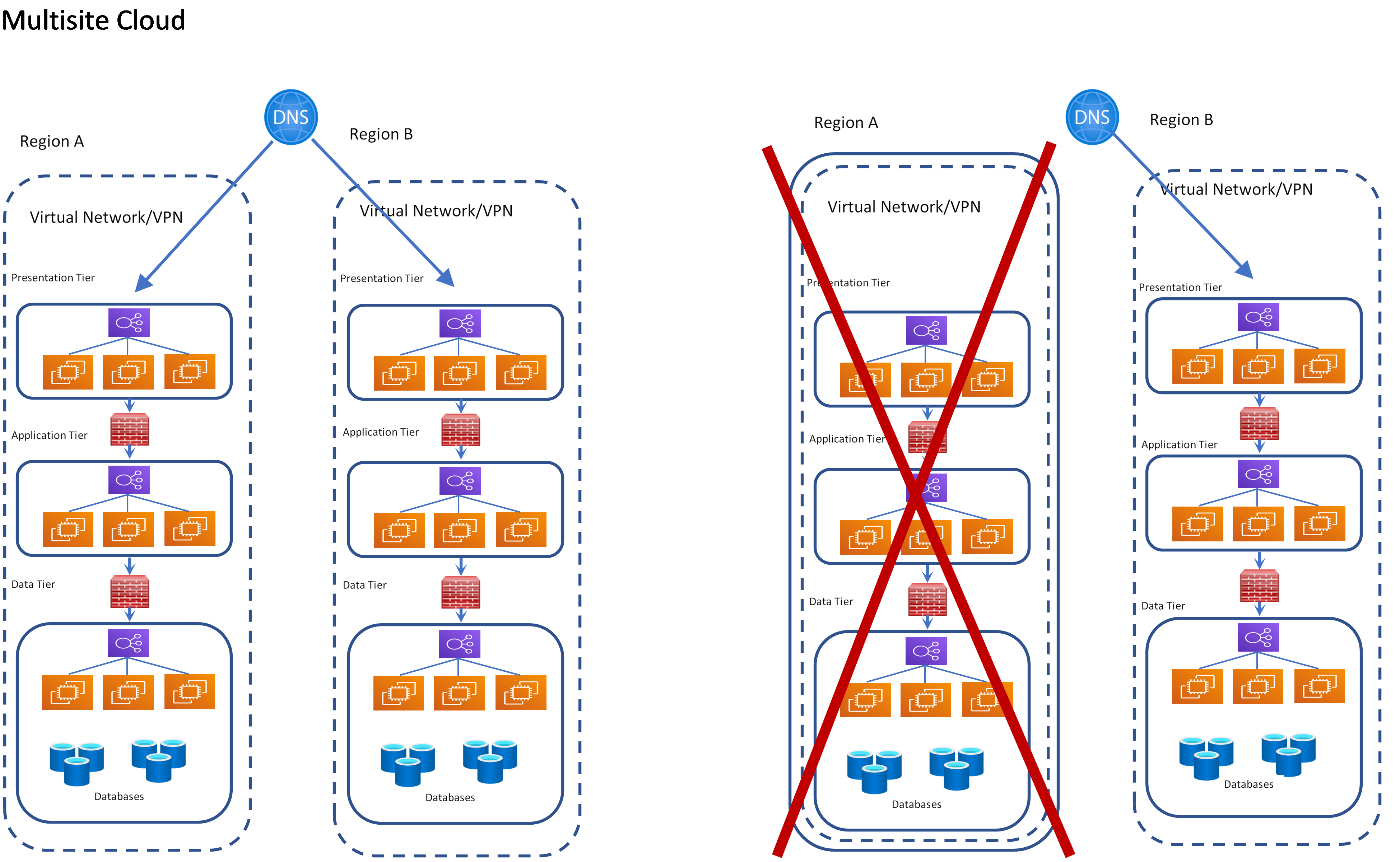
Multi-Site Cloud
Multi-site cloud configuration, like hot sites, are duplicated fully operational environments. The environments are replicated in a different physical location and are load balanced to receive network traffic. This is also known as an active-active configuration. In the event of a failure, traffic is rerouted immediately to the other identical environments minimizing interruptions. Most cloud service providers offer physical separation via larger geographic areas typically called regions and more granular delineations within the regions known as availability zones. Different cloud service providers may have slightly different terminology, but the concepts and functionality remain similar. Multi-site cloud environments require no additional personnel or equipment, as they are cloud based and failover is automatic. Additional cloud resources are needed to duplicate the environments in the cloud.
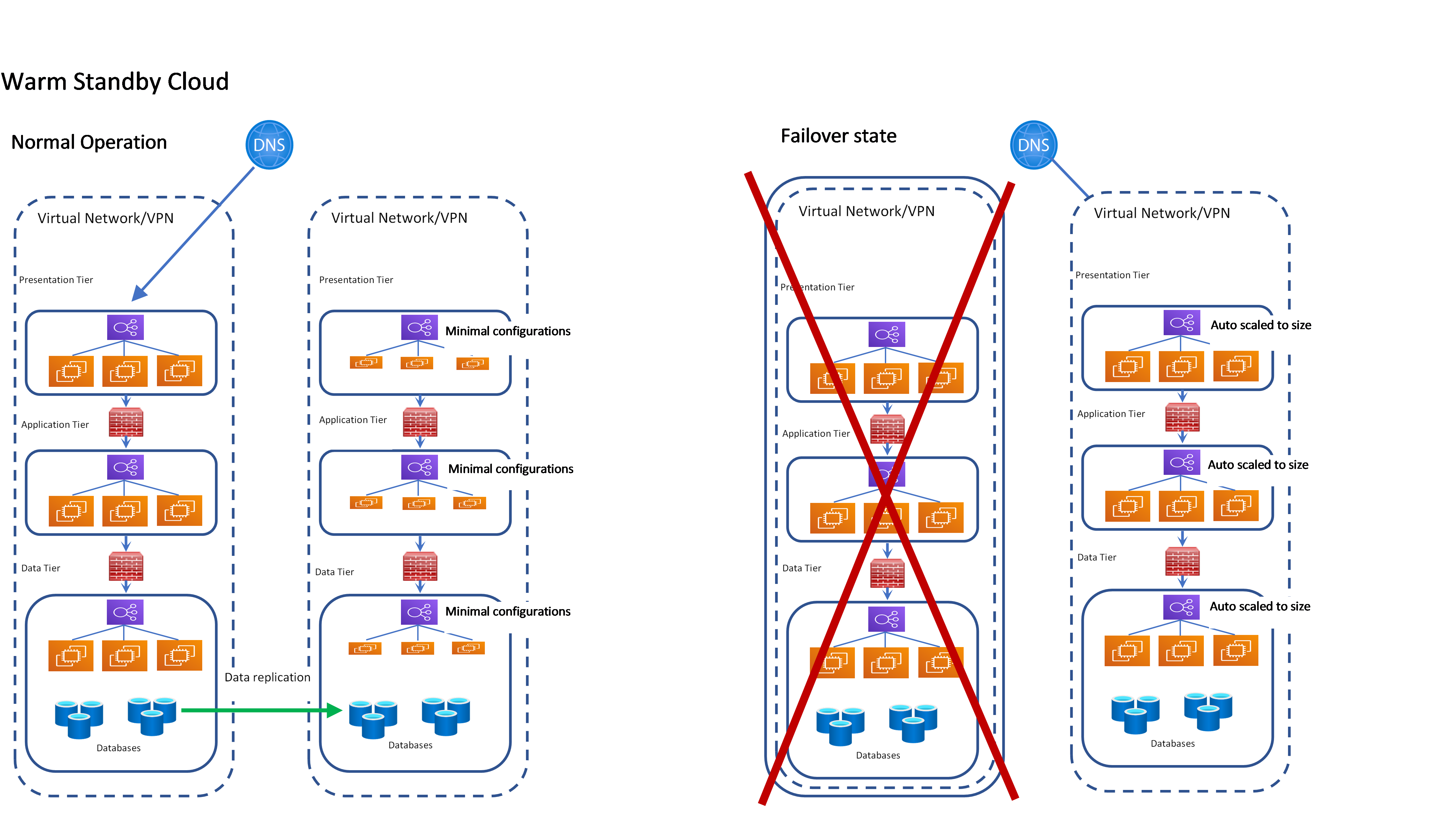
Warm Standby Cloud
Scaled down duplicates of the master resources are created in different geographical regions/zones but are in a minimalized operational (standby) state. Data is synchronized, key services are operational. However, network traffic is only redirected when a failure is detected, and the standby environment is activated. This is active-passive.
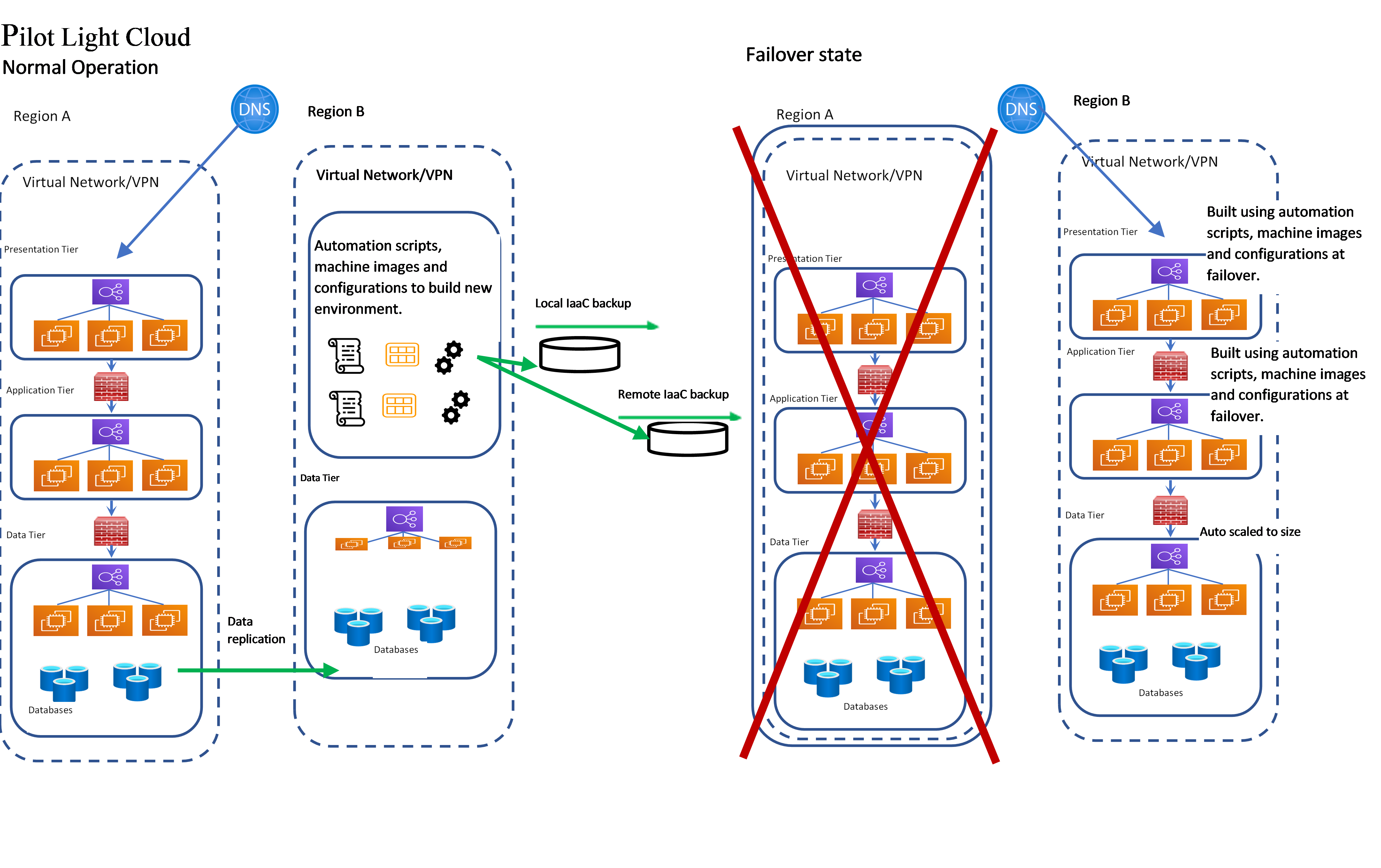
Pilot Light Cloud
Absolute minimal duplicates of critical resources are kept alive, such as data synchronization. Once a failure is detected, duplicate resources are created from scratch using predefined configurations which are used to build the new environment.
The predefined configurations and Infrastructure as Code (IaaS), which are used to build the new environment after a failover, should be backed up both locally and remote where it can be accessed to build the new environment.
TRA 2025 Release 1 • General Distribution / Unclassified Information