DR Parameters
The DR parameters can assist in determining specific requirements in an event of an identified disaster event. The DR parameters help determine required capabilities for DR. The key DR parameters are:
-
Recovery Point Objective (RPO) – The amount of time, prior to a disruption or system outage, to which mission/business process data can be recovered (given the most recent backup copy of the data) after an outage.
-
Recovery Time Objective (RTO) – The maximum amount of time that a system resource can remain unavailable before there is an unacceptable impact on other system resources, supported mission/business processes, and the MTD.
-
Work Recovery Time (WRT) – The maximum amount of time needed to verify the system and/or data integrity.
-
Maximum Tolerable Downtime (MTD) – The total amount of time the system owner/authorizing official is willing to accept for a mission/business process outage or disruption.
Disaster Recovery Parameters shows a timeline for DR parameters:
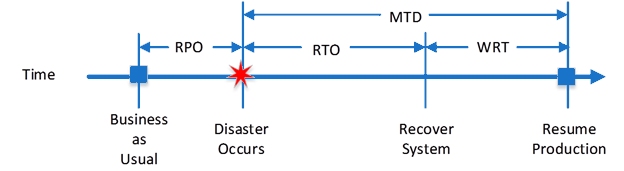
The DR parameters help CMS business and system owners build the DR requirements into CMS life cycle (e.g., TLC). Per the CIO Memorandum Recovery Time Objective Requirements, July 22, 2020, these recovery parameters should be determined within the Business Impact Analysis (BIA).
The activities for DR requirements at different phases of CMS life cycle:
-
Initiate
- Identify a service requirement and the need for an IT system
- Conduct a Business Impact Analysis (System BIA) to determine the operational parameters including RTO, RPO, MTD and WRT
- Enter all system attributes in the appropriate systems of record including CFACTS
-
Develop
- Complete a system design including DR parameters following the SDLC (TLC)
- Update the System BIA to reflect design trade-offs
- Document how to meet the DR parameters in the DR Plan and ISCP
- Test to verify the DR plan and ISCP
-
Operate
- Conduct ongoing testing, training & exercises (TT&E) of DR and ICSP
- Participate in COP exercises
- Complete role based training
- Document lessons learned, including changes to the System BIA
-
Retire
- Transition any required functionality to existing systems
- Update DR plans
- Follow the system Disposition Plan to retire the system
DR Tiers
The concept of tier-based disaster recovery was developed by users of IBM mainframes as a rule of thumb for planning. CMS no longer uses this; the CMS Information System Contingency Plan (ISCP) Handbook is based on NIST SP 800-34, Contingency Planning Guide for Federal Information Systems and NIST SP 800-53, Security and Privacy Controls for Information Systems and Organizations. There are no industry standards for the number of DR tiers. DR tiers are designed to meet the needs of the business and therefore vary by organization.
The DR tiers shown in Table - CMS Disaster Recovery Tiers serves as a tool organized by system RTO requirements. The choice of which tier a system belongs to is influenced by the following business system characteristics:
- Whether it supports one or more MEFs
- Whether is has identified financial and operation impacts
- Its dependencies on other systems
Recovery Facilities
Facility recovery involves the restoration or replacement of damaged facilities or the use of alternate facilities. This includes communications capabilities such as voice and network. There are various types of backup sites. There are for on-premises physical datacenters; cold, warm, and hot. There are for cloud-based datacenters; multi-site, warm-standby, and pilot light. Each type varies in cost depending on the effort required for implementation.
| Site Type | Definition |
|---|---|
| On-Premises Cold Site | Typically, facilities with adequate space and infrastructure (electric power, telecommunications connections, and environmental controls) to support information system recovery activities. This is the least expensive type of backup site and takes the longest amount of time to configure and restore to normal operations. |
| On-Premises Warm Site | Compromise between a hot site and a cold site. While the physical building, connectivity, and hardware may be available, the data may still need to be copied over to the system. |
| On-Premises Hot Site |
A complete duplication of the original site, with full computer systems as well as near-complete backups of user data. A hot site requires a mirroring architecture with real-time synchronization between the two sites. This facilitates business system relocation with minimal loss to normal operations. It requires no additional labor during an event as the architecture is fully automated. |
| Site Type | Definition |
|---|---|
| Multi-Site Cloud | A complete duplication of original virtual network environments (compute, data, networks and services) in an alternate region. Both sites are active and available for use. Traffic is directed through a load balancing mechanism via DNS. Multi-site cloud requires a mirroring architecture with real-time synchronization between the two sites. This facilitates business system relocation with minimal loss to normal operations. It requires no additional labor during an event as the architecture is fully automated. |
| Warm-Standby Cloud | A duplicate, but minimal version of the original virtual network environments (compute, data, networks and services) in an alternate region. Failover site is in standby mode and only receives data synchronization from live environment. During failover, the load balancing mechanisms redirect traffic and the failover environment is auto-scaled to size based on load requirements. |
| Pilot Light Cloud | A duplicate, but minimal version of the original virtual network environments but only data and essential services are live in an alternate region. Failover site is in standby mode and only receives data synchronization from live environment. During failover, a new environment is built out using infrastructure as code (scripting, defined configurations and base machine images). This is then appropriately connected to the synchronized data. The load balancing mechanisms then redirect traffic. |
System and Data Recovery
The results of Business Impact Analyses (BIAs) can provide insight into whether CMS will incur substantial financial and operational impacts from a disruption of CMS business functions and operations exceeding a certain number of days. Those functions and operations with a critical timeframe must be resumed or recovered to a minimum level of service within specified timeframe. The goal is to ensure that CMS survives as a viable entity in the event of a disaster. For critical functions, such as MEFs, this may require cloning the normal business and working environment to ensure success.
Based on analysis of the situation after a disaster occurs, the recovery resources requirements can be divided into the three distinct recovery phases as described in Table - Recovery Resource Requirements.
TRA 2025 Release 1 • General Distribution / Unclassified Information